Når vi bruker verktøy som Skype og QQ for å jevnlig gjennomføre tale- og videochatter med venner, har vi noen gang lurt på hvilke kraftige teknologier som ligger bak? Denne artikkelen vil gi en kort introduksjon til teknologiene som brukes i nettverkssamtaler, som kan betraktes som et glimt av leoparden.
1. Konseptuell modell
Internett-taleanrop er vanligvis toveis, noe som er symmetrisk på modellnivå. For enkelhets skyld kan vi diskutere kanalen i en retning. Den ene parten snakker og den andre parten hører stemmen. Det virker enkelt og raskt, men prosessen bak er ganske komplisert.
Dette er den mest grunnleggende modellen som består av fem viktige lenker: anskaffelse, koding, overføring, dekoding og avspilling.
(1) Stemmesamling
Stemmesamling refererer til innsamling av lyddata fra en mikrofon, det vil si konvertering av lydprøver til digitale signaler. Det involverer flere viktige parametere: samplingsfrekvens, antall samplingsbiter og antall kanaler.
For å si det enkelt: prøvetakingsfrekvensen er antall anskaffelseshandlinger på 1 sekund; antall samplingsbiter er lengden på dataene som er oppnådd for hver anskaffelseshandling.
Størrelsen på en lydramme er lik: (samplingsfrekvens × antall samplingsbiter × antall kanaler × tid)
Vanligvis er varigheten av en samplingsramme 10ms, det vil si at hver 10ms data utgjør en lydramme. Forutsatt: samplingshastigheten er 16k, antall samplingsbiter er 16bit, og antall kanaler er 1, så er størrelsen på en 10ms lydramme: (16000 * 16 * 1 * 0.01) / 8 = 320 byte. I beregningsformelen er 0.01 et sekund, det vil si 10ms.
(2) Koding
Forutsatt at vi sender den innsamlede lydrammen direkte uten koding, kan vi beregne ønsket båndbreddekrav. Fortsatt eksemplet ovenfor: 320 * 100 = 32 kBytes / s, hvis det konverteres til bits / s, er det 256 kb / s. Dette er mye bruk av båndbredde. Med nettverkstrafikkovervåkingsverktøy kan vi finne at når taleanrop blir foretatt med IM-programvare som QQ, er trafikken 3-5 kB / s, som er en størrelsesorden mindre enn den opprinnelige trafikken. Dette skyldes hovedsakelig lydkodingsteknologi. Derfor er denne lenken for koding i den faktiske applikasjonen for taleanrop uunnværlig. Det er mange ofte brukte talekodingsteknologier, for eksempel G.729, iLBC, AAC, SPEEX og så videre.
(3) Nettverksoverføring
Når en lydramme er kodet, kan den sendes til innringeren via nettverket. For sanntidsapplikasjoner som talesamtaler er lav ventetid og stabilitet veldig viktig, noe som krever at nettverket vårt overfører veldig jevnt.
(4) Dekoding
Når den andre parten mottar den kodede rammen, vil den dekode den for å gjenopprette den til data som kan spilles direkte av lydkortet.
(5) Stemmeavspilling
Etter at dekodingen er fullført, kan den oppnådde lydrammen sendes til lydkortet for avspilling. Vedlegg: Du kan referere til introduksjon og demo-kildekode og SDK-nedlasting av MPlayer, en komponent for taleopptak
2. Vanskeligheter og løsninger i praktiske anvendelser
Hvis bare å stole på den ovennevnte teknologien kan realisere et lyddialogsystem som brukes på brednettverket, er det ikke mye behov for å skrive denne artikkelen. Det er nettopp at mange realistiske faktorer har introdusert mange utfordringer for den ovennevnte konseptuelle modellen, noe som gjør realiseringen av nettverksstemmesystemet ikke så enkelt, som involverer mange profesjonelle teknologier. Selvfølgelig har de fleste av disse utfordringene allerede modne løsninger. Først og fremst må vi definere et "god effekt" stemmedialogsystem. Jeg tror det skal oppnå følgende punkter:
(1) Lav ventetid. Bare med lav ventetid kan de to partene på samtalen ha en sterk sans for sanntid. Selvfølgelig avhenger dette hovedsakelig av hastigheten på nettverket og avstanden mellom de fysiske stedene til de to partene under samtalen. Fra perspektivet til ren programvare er muligheten for optimalisering veldig liten.
(2) Lav bakgrunnsstøy.
(3) Lyden er jevn, uten følelsen av fast eller pause.
(4) Det er ikke noe svar.
Nedenfor vil vi snakke om tilleggsteknologiene som brukes i selve nettverksstemmesamtalen.
1. Ekko-kansellering AEC Nesten alle er nå vant til å bruke stemmeavspillingsfunksjonen på PC eller bærbar PC under talechat. Som alle vet, har denne lille vanen utgjort en stor utfordring for taleteknologi. Når du bruker høyttalerfunksjonen, vil lyden som spilles av høyttaleren samles opp av mikrofonen igjen og overføres tilbake til den andre parten, slik at den andre parten kan høre sitt eget ekko. Derfor, i praktiske anvendelser, er funksjonen til ekko-kansellering nødvendig. Etter at den innsamlede lydrammen er oppnådd, er dette gapet før koding tiden for ekko-kanselleringsmodulen til å fungere. Prinsippet er ganske enkelt at ekko-kanselleringsmodulen utfører noen kanselleringslignende operasjoner i den samlede lydrammen i henhold til den lydrammen som nettopp er spilt, for å fjerne ekkoet fra den samlede rammen. Denne prosessen er ganske komplisert, og den er også relatert til størrelsen på rommet du er i når du chatter, og din plassering i rommet, fordi denne informasjonen bestemmer lengden på lydbølgerefleksjonen. Den intelligente ekko-kanselleringsmodulen kan dynamisk justere de interne parametrene for å tilpasse seg det beste miljøet best mulig.
2. Støydemping DENOISE Støydemping, også kjent som støyreduksjonsbehandling, er basert på karakterene til stemmedata for å identifisere den delen av bakgrunnsstøyen og filtrere den ut av lydrammer. Mange kodere har denne funksjonen innebygd.
3. JitterBuffer Jitterbufferen brukes til å løse problemet med nettverksjitter. Den såkalte nettverksjitteren betyr at nettverksforsinkelsen blir større og mindre. I dette tilfellet, selv om avsenderen sender datapakker regelmessig (for eksempel sendes en pakke hver 100 ms), kan mottakeren ikke motta samme timing. Noen ganger kan ingen pakker mottas i en syklus, og noen ganger mottas flere pakker i en syklus. På denne måten er lyden som mottakeren hører ett kort ett kort. JitterBuffer fungerer etter dekoderen og før stemmeavspilling. Det vil si at etter at dekodingen er fullført, blir den dekodede rammen satt i JitterBuffer, og når avspilling av lydkortet kommer tilbake, blir den eldste rammen hentet fra JitterBuffer for avspilling. Bufferdybden til JitterBuffer avhenger av graden av nettverksjitter. Jo større nettverksjitter, jo større bufferdybde og jo større forsinkelse i lydavspilling. Derfor bruker JitterBuffer en høyere forsinkelse i bytte for jevn lydavspilling, fordi den subjektive opplevelsen er bedre sammenlignet med lyden ett kort ett kort, en litt større forsinkelse, men en jevnere effekt. Selvfølgelig er bufferdybden til JitterBuffer ikke konstant, men dynamisk justert i henhold til endringer i graden av nettverksjitter. Når nettverket gjenopprettes for å være veldig glatt og uhindret, vil bufferdybden være veldig liten, slik at økningen i avspillingsforsinkelse på grunn av JitterBuffer vil være ubetydelig.
4. Demp deteksjon VAD Hvis en part ikke snakker i en talesamtale, genereres ingen trafikk. Mute deteksjon brukes til dette formålet. Mute deteksjon er vanligvis også integrert i kodingsmodulen. Den stille deteksjonsalgoritmen kombinert med den forrige støydempingsalgoritmen kan identifisere om det er taleinngang for øyeblikket. Hvis det ikke er taleinngang, kan den kode og sende ut en spesiell kodet ramme (for eksempel er lengden 0). Spesielt på en videokonferanse med flere personer snakker vanligvis bare én person. I dette tilfellet er bruken av lydløs deteksjonsteknologi for å spare båndbredde fremdeles veldig betydelig.
5. Blandingsalgoritme I en stemmechat med flere personer, trenger vi å spille taledata fra flere personer samtidig, og lydkortet spiller bare en buffer. Derfor må vi blande flere stemmer i en. Dette er hva blandingsalgoritmen gjør. Selv om du kan finne en måte å omgå blandingen og la flere lyder spille samtidig, må den for ekko-kansellering blandes til en avspilling, ellers kan ekko-kansellering bare eliminere noen av de mange lydene på mest. Hele veien. Blanding kan gjøres på klientsiden eller på serversiden (noe som kan spare nedstrøms båndbredde). Hvis P2P-kanaler brukes, kan blanding bare gjøres på klientsiden. Hvis det blandes på klienten, er miksing vanligvis den siste lenken før du spiller. Denne artikkelen er en grov oppsummering av vår erfaring med å implementere stemmedelen av OMCS. Her laget vi bare en enkel beskrivelse av hver lenke i figuren, og en av dem kan skrives til et langt papir eller til og med en bok. Derfor er denne artikkelen bare for å gi et introduksjonskart for de som er nye innen nettverksutvikling av talesystemer, og gi noen ledetråder.



|
|
|
|
Hvor langt (lang) senderen dekke?
Rekkevidden avhenger av mange faktorer. Den virkelige avstand er basert på antennen installeres høyde, antenneforsterkning, ved hjelp miljø som bygning og andre hindringer, følsomheten til mottakeren, antennen til mottakeren. Installere antennen mer høy og bruke på landsbygda, avstanden vil mye mer langt.
Eksempel 5W FM-sender bruke i byen og hjemby:
Jeg har en USA kundens bruk 5W FM-sender med GP-antenne i hjembyen, og han teste den med en bil, det dekker 10km (6.21mile).
Jeg teste 5W FM-sender med GP-antenne i hjembyen min, det dekker ca 2km (1.24mile).
Jeg teste 5W FM-sender med GP-antenne i byen Guangzhou, det dekker omtrent bare 300meter (984ft).
Nedenfor er det tilnærmede område av forskjellige kraft FM-sendere. (Utvalget er diameter)
0.1W ~ 5W FM-sender: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
15W ~ 80W FM-sender: 3KM ~ 10KM
80W ~ 500W FM-sender: 10KM ~ 30KM
500W ~ 1000W FM-sender: 30KM ~ 50KM
1KW ~ 2KW FM-sender: 50KM ~ 100KM
2KW ~ 5KW FM-sender: 100KM ~ 150KM
5KW ~ 10KW FM-sender: 150KM ~ 200KM
Hvordan kontakte oss for senderen?
Ring meg + 8618078869184 ELLER
Email meg [e-postbeskyttet]
1.How langt du ønsker å dekke i diameter?
2.How høyt av dere Tower?
3.Where er du fra?
Og vi vil gi deg mer faglige råd.
Om Oss
FMUSER.ORG er et systemintegrasjonsfirma som fokuserer på RF trådløs overføring / studio video lydutstyr / streaming og databehandling. Vi leverer alt fra råd og rådgivning gjennom rackintegrasjon til installasjon, igangkjøring og opplæring.
Vi tilbyr FM-sender, Analog TV-sender, Digital-TV-sender, VHF UHF-sender, Antenner, Koaksialkabelkontakter, STL, On Air-behandling, Broadcast-produkter for Studio, RF Signal Monitoring, RDS-kodere, Lydprosessorer og Remote Site Control Units, IPTV-produkter, Video / Audio Encoder / dekoder, designet for å møte behovene til både store internasjonale kringkastingsnettverk og små private stasjoner.
Vår løsning har FM-radiostasjon / Analog TV-stasjon / Digital TV-stasjon / Audio Video Studio-utstyr / Studio Transmitter Link / Transmitter Telemetry System / Hotel TV System / IPTV Live Broadcasting / Streaming Live Broadcast / Video Conference / CATV Broadcasting system.
Vi bruker avanserte teknologiprodukter til alle systemene, fordi vi vet at høy pålitelighet og høy ytelse er så viktige for systemet og løsningen. Samtidig må vi også sørge for at vårt produktsystem har en svært rimelig pris.
Vi har kunder fra offentlige og kommersielle kringkastingstjenester, telekomoperatører og reguleringsmyndigheter, og vi tilbyr også løsninger og produkter til mange hundre mindre, lokale og lokale kringkastere.
FMUSER.ORG har eksportert mer enn 15 år og har kunder over hele verden. Med 13 års erfaring innen dette feltet har vi et profesjonelt team for å løse kundens alle slags problemer. Vi er dedikert til å levere den ekstremt rimelige prisen på profesjonelle produkter og tjenester. Kontakt Epost : [e-postbeskyttet]
vår fabrikk

Vi har modernisering av fabrikken. Du er velkommen til å besøke vår fabrikk når du kommer til Kina.

I dag er det allerede 1095 kunder hele verden besøkt våre Guangzhou Tianhe kontor. Hvis du kommer til Kina, er du velkommen til å besøke oss.
på Fair

Dette er vår deltakelse i 2012 Global Sources Hong Kong Electronics Fair . Kunder fra hele verden endelig har en sjanse til å komme sammen.
Hvor er Fmuser?
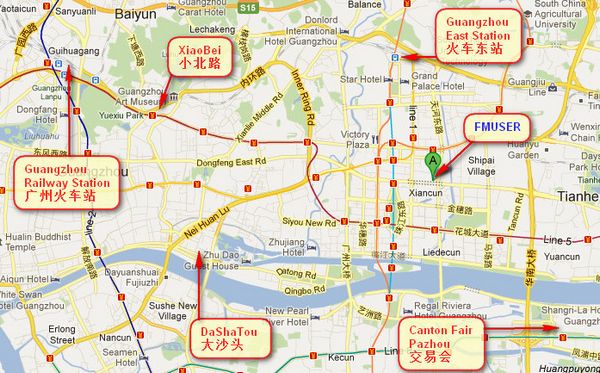
Du kan søke i disse tallene " 23.127460034623816,113.33224654197693 "på google map, så finner du vårt fmuser-kontor.
FMUSER Guangzhou Kontoret ligger i Tianhe District, som er den midten av Canton . Veldig nær til Canton Fair , Guangzhou jernbanestasjon, Xiaobei veien og dashatou , Trenger bare 10 minutter hvis ta TAXI . Velkommen venner over hele verden til å besøke og forhandle.
Kontakt: Sky Blå
Mobil: + 8618078869184
WhatsApp: + 8618078869184
Wechat: + 8618078869184
E-post: [e-postbeskyttet]
QQ: 727926717
Skype: sky198710021
Adresse: No.305 Room Huilan Building No.273 Huanpu Road Guangzhou Kina Postnummer: 510620
|
|
|
|
Engelsk: Vi aksepterer alle betalinger, for eksempel PayPal, kredittkort, Western Union, Alipay, Money Bookers, T / T, LC, DP, DA, OA, Payoneer. Hvis du har spørsmål, kan du kontakte meg [e-postbeskyttet] eller WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Vi anbefaler at du bruker Paypal til å kjøpe våre produkter, er The Paypal en sikker måte å kjøpe på internett.
Hver av våre element liste siden bunnen på toppen har en paypal logo for å betale.
Kredittkort.Hvis du ikke har paypal, men du har kredittkort, kan du også klikke Yellow PayPal knappen for å betale med kredittkort.
-------------------------------------------------- -------------------
Men hvis du ikke har et kredittkort og ikke har en PayPal-konto eller vanskelig å fikk en paypal Kontoinnstillinger, kan du bruke følgende:
Western Union.  www.westernunion.com www.westernunion.com
Betal med Western Union til meg:
Fornavn / Fornavn: Yingfeng
Etternavn / etternavn / etternavn: Zhang
Fullt navn: Yingfeng Zhang
Land: Kina
By: Guangzhou
|
-------------------------------------------------- -------------------
T / T. betal med T / T (wire transfer / telegrafisk overføring / Bank Transfer)
Første BANKINFORMASJON (SELSKAPSKONTO):
SWIFT BIC: BKCHHKHHXXX
Bank navn: BANK OF CHINA (HONG KONG) LIMITED, HONG KONG
Bankadresse: BANKEN AV KINA TOREN, 1 GARDEN ROAD, CENTRAL, HONG KONG
BANK KODE: 012
Kontonavn: FMUSER INTERNATIONAL GROUP LIMITED
Kontonr. : 012-676-2-007855-0
-------------------------------------------------- -------------------
Andre BANKINFORMASJON (SELSKAPSKONTO):
Mottaker: Fmuser International Group Inc.
Kontonummer: 44050158090900000337
Mottakerens bank: China Construction Bank Guangdong Branch
SWIFT-kode: PCBCCNBJGDX
Adresse: NO.553 Tianhe Road, Guangzhou, Guangdong, Tianhe District, Kina
** Merk: Når du overfører penger til bankkontoen vår, vennligst IKKE skriv noe i kommentarområdet, ellers vil vi ikke kunne motta betalingen på grunn av myndighetens policy for internasjonal handel.
|
|
|
|
* Det vil bli sendt i 1-2 arbeidsdager når betaling klart.
* Vi vil sende den til din paypal adresse. Hvis du ønsker å endre adresse, send riktig adresse og telefonnummer til min e-post [e-postbeskyttet]
* Hvis pakkene er under 2kg, vil vi bli sendt via post luftpost, vil det ta ca 15-25days til hånden din.
Hvis pakken er mer enn 2kg, vil vi sende via EMS, DHL, UPS, Fedex rask ekspresslevering, vil det ta ca 7 ~ 15days til hånden din.
Hvis pakken mer enn 100kg, vil vi sende via DHL eller flyfrakt. Det vil ta om 3 ~ 7days til hånden din.
Alle pakkene er skjema Kina Guangzhou.
* Pakken sendes som en "gave" og avvises så lite som mulig, kjøper trenger ikke betale for "TAX".
* Etter skip, vil vi sende deg en e-post og gi deg sporingsnummeret.
|
|
|
For garanti.
Kontakt oss --- >> Returner varen til oss --- >> Motta og send en ny erstatning.
Navn: Liu Xiaoxia
Adresse: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou Kina.
ZIP: 510620
Telefon: + 8618078869184
Vennligst gå tilbake til denne adressen og skriv din paypal adresse, navn, problem på merknad: |
|













